Loss Function
손실 함수
퍼셉트론과 신경망의 다른 점은
퍼셉트론에서는 가중치를 인간이 직접 매번 입력해주어야 하지만
신경망은 처음에만 입력해주면 몇 가지 도구를 이용하여 스스로 값을 의미있게 바꾼다는 것이다.
여기서 ‘의미있게’ 란
신경망의 출력이 점점 정답에 다가가도록 하는 것을 의미한다. (학습)
이를 위해 손실 함수를 도입한다.
손실 함수는 신경망의 출력과 정답을 인수로 가진다.
함수 안에서 출력과 정답을 비교하여 신경망의 출력이 정답에 얼마나 가까운지를 출력한다.
즉 신경망이 올바르게 예측할 수록 손실 함수의 출력은 줄어들고
틀리게 예측할 수록 손실 함수의 출력은 커진다.
**다른 말로 해서 손실 함수는 컴퓨터가 주어진 데이터를 예측하고, 이를 채점하는 과정과 같다. **
손실 함수에는 평균 제곱 오차 (mean squared error), 교차 엔트로피 오차(cross entropy error)가 있다.
평균 제곱 오차는 다음과 같은 식을 가진다.
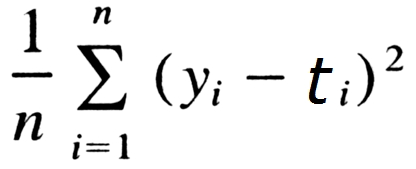
다음은 파이썬으로 구현한 평균 제곱 오차이다. 인수는 ndarray 로 받는다.
def meanSquaredError(y, t) :
return np.sum((y-t)**2)/2
교차 엔트로피는 t x ln(y) 의 총합에 마이너스를 붙인다.
파이썬으로 구현한 교차 엔트로피 오차이다.
def crossEntropyError(y, t) :
return -np.sum(t*np.log(y + 1e-7))
출력 레이블 값 중 0이 껴있을 때를 고려해 1e-7 를 더해준다.
단, 정답 레이블이 [0, 1, 0, 0, 0] 같이
하나의 1, 나머지는 0인 원핫레코딩 방식의 레이블이 아니라면 다음과 같이 구현한다.
def crossEntropyError(y, t) :
if y.dim == 1 :
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batchSize = y.shape[0]
return -np.sum(np.log(y[np.arange(batchSize), t] + 1e-7)) / batchSize
미분
미분에는 해석적 미분이 있고 수치 미분이 있다.
해석적 미분은 실제 수학적으로 미분을 하는 것이다.
도함수를 구하는 것이다.
프로그램에서는 함수를 가지고 실제 도함수를 구하고 거기에 변수를 적용해서 값을 얻기 어렵다.
그래서 미분을 할 때 해당 값에 아주 작은 값을 변화시키고 그 차이를 구하여 접선의 기울기를 얻는다.
이를 수치 미분이라고 한다.
예를 들어 f1(x) = 2x^2 + 3x 라는 식이 있다고 하면
def f1(x) :
return 2*x**2 + 3*x
라는 f1 이라는 함수를 만들 수 있고
이의 도함수는
def numericalDiff(f, x) :
h = 1e-4
return (f(x+h) - f(x)) / h
로 구할 수 있다.
미분의 정의에서 해당 h 는 lim h->0 으로 적으나
컴퓨터에서는 이 결과와 해석적 미분의 결과의 오차가 크지 않는 선에서
h 에 어떤 수치를 도입하여 미분한다.
가중치를 구하라
신경망이 퍼셉트론과 다른 점, 그리고 학습이 가능한 이유는
신경망에선 가중치가 변할 수 있다고 하였다.
가중치에 따라 신경망이 내보내는 해답은 달라진다.
인물 사진을 주고 성별을 평가하라 했을 때
맨 아래 옷 쪽에 가중치를 많이 두고 남녀의 성별을 예측하라고 하면
정확한 결과를 얻지 못할 것이다.
처음에 사람이 적절한 가중치를 두고
훈련과 채점(손실 함수)을 반복하면서
손실 함수의 값을 줄이는 쪽으로 가중치를 점점 변화시켜야 한다.
처음에는 옷 쪽에 가중치를 두더라도
이 과정을 반복하면서 점점 눈이나 머리 스타일 같은 곳에 가중치를 크게 두도록 해야 한다.
가중치가 변하면 그 출력도 그에 맞게 변할 것이고
출력이 변하면 손실 함수의 결과도 달라진다.
신경망 학습의 키는 손실 함수의 값을 작게 하는 쪽으로 가중치를 변화시키는 것이다.
그렇다면 손실 함수의 값을 작게하는 쪽은 어떻게 알 수 있을까
정답은 미분 안에 있었다.
변수가 두 개 이상인 함수를 편미분하여 각 변수에 해당하는 미분 결과를 벡터의 형태로 나타냈을 때
(f(x0, x1) a, b에 미분한다면 이 벡터는 [ f(a, b)/dx0 , f(a, b)/dx1 ] 로 나타난다.)
이 벡터는 그 그래프의 최소 지점을 가리킨다.
또한 그 최소 지점에서 멀 수록 이 벡터의 크기는 커진다.
따라서 기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향이다.
이를 이용하여 가중치를 변화시키는 방법 (손실 함수의 값을 점차 줄이는 법)을 경사법이라고 한다.
경사법은 가중치를 상수와 기울기의 곱만큼 줄이는 방법이다.
여기서 이 상수를 학습률이라고 부른다. 얼만큼 학습할지를 정하는 값이다.
이 학습률은 사람이 실제 정하는 값으로
너무 크게 한다면 섣불리 학습을 해서 마지막에 가선 최소 지점을 넘어서 엉뚱한 출력을 할 것이고
너무 작게 한다면 최소 지점에 도달하기도 전에 총 학습이 끝날 것이다.
정리
- 신경망의 각 층을 넘어갈 때 노드들과 각 가중치의 곱 + 편향의 값을 구한다.
- 해당 값으로 활성화 함수를 구하여 다음 노드의 값을 정한다.
- 위 과정을 반복 후 출력층 함수를 통하여 출력한다.
- 첫 가중치로 인한 출력과 정답을 비교하는 손실 함수의 기울기를 구한다.
- 구해진 기울기와 학습률을 반영하여 가중치를 수정한다.
- 위 과정을 학습 데이터 / 배치 크기만큼 반복한다.